
データを並び替える際、アルファベット順に並べ替えず、元データの並びそのままで、同じ値のデータは纏まって表示して欲しい場合があると思います。
この記事では、その問題をExcel関数のみで解決する方法を解説します。
また、SORT関数も使用しないので、Excel2021以前の永年版Excelでも使用できます。
後半では、処理能力が高くないノートパソコンでも数万件のデータを扱える方法を解説します! 現在作成中です。
ファイルダウンロードをしたい方はこちら。
全体の処理の流れ
処理が複雑なので、全体の流れをフローチャートで最初に示します。
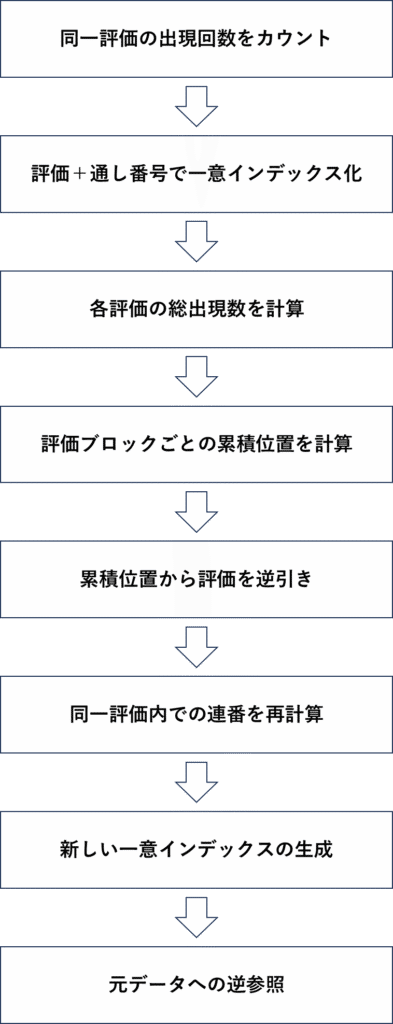
数千件までのデータを扱う場合
1. 同一評価の出現回数をカウント
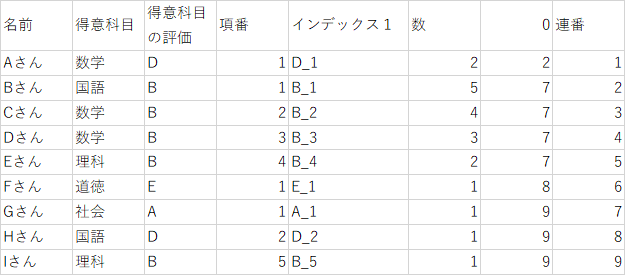
今回はこちらのデータで実際に並べ替えを行ってみたいと思います。
評価はアルファベットですが、数字の場合でも同じようにできます。
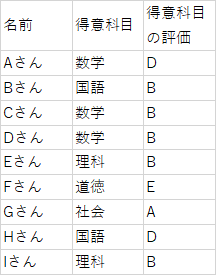
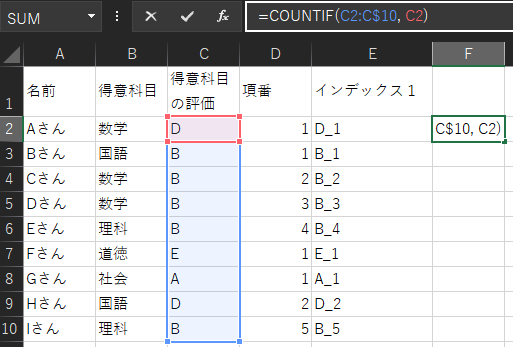
まずは、「得意科目の評価」に複数の同じ値があるので、それぞれ区別できるようにします。
並べ替えたいデータ列(C列)右側のセルの一番上(D2セル)に、「=COUNTIF(C$2:C2, C2)」関数を入力します。
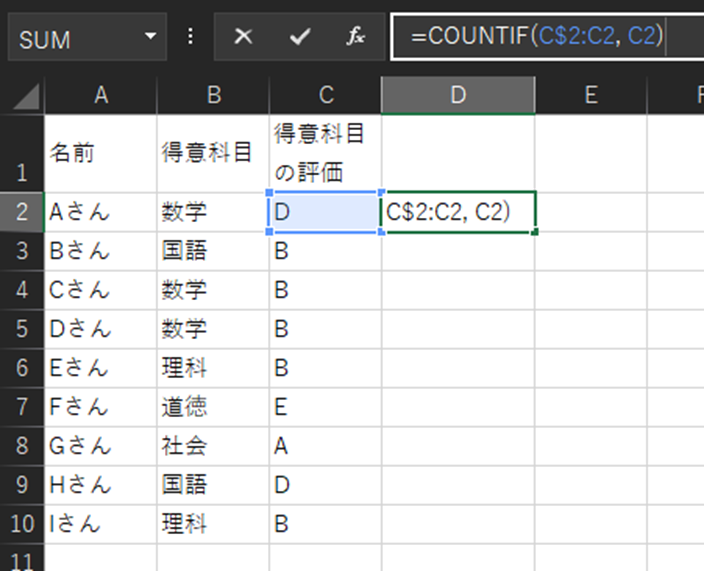
COUNTIF関数は、指定された範囲内のセルに、指定されたセルと全く同じ値のセルが何個あるかを検索してくれます。COUTIF(範囲, 検索条件)
この場合は、C2からC2までの範囲のセル内に、C2の値である「D」という値のセルが何個あるかを調べてくれます。
これでは分かりにくいので、後で別のセルの場合でも説明します。
次は、この関数を下にコピーします。
関数を入力したセルの右下の、■にカーソルを合わせると、白色の十字から黒色の十字に変換します。
黒色の十字に変化した後、ダブルクリックすると、一番下までコピーされます。
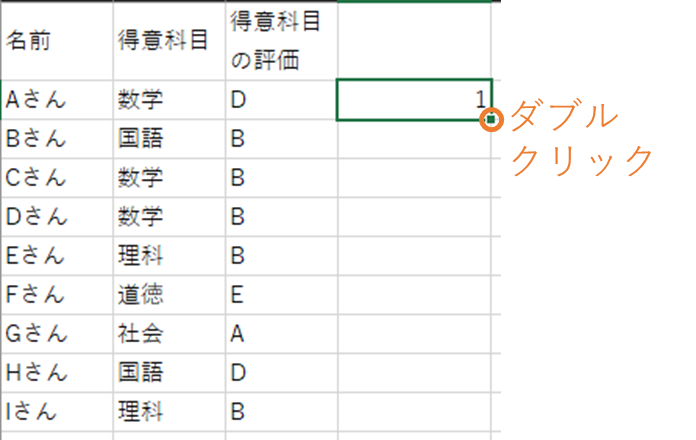
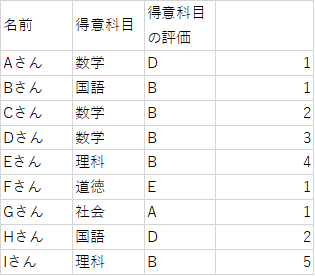
この計算によって、同じ評価のうち上から数えて何番目かということが分かります。
実際に、B評価を見てみると上から数えて何番目のBかという事が、計算結果から分かります。
数式の処理を理解するために、コピーされた後のD10セルの数式を見てみましょう。
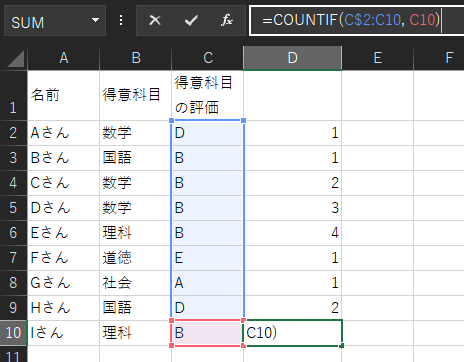
D2セルの数式よりもD10セルの数式を見た方がどの様な計算をしているか分かりやすいと思います。
この場合は、C2からC10までの範囲のセル内に、C10の値である「B」という値のセルが何個あるかを検索してくれます。
この関数の範囲指定には、絶対参照を意味する$を使用します。COUNTIFの検索範囲で指定する2つのセルのうち、一方のみを絶対参照にすることで、数式が入力してあるセルよりも上側全ての「得意科目の評価」を検索範囲に指定できるようになります。
C$2:C10でなく$C$2:$C10でも問題なく計算できますが、$C$2:$C10の場合は、横側にある別の区別データに対してコピーペーストすると、COUNTIFの検索範囲がC2からペースト先のセルになります。これによって正常に計算できなくなります。
検索範囲の記載方法や、$の使い方、絶対参照の解説はこちら。
2. 評価+通し番号で一意インデックス化
1.で振った項番だけでは、異なる「得意科目の評価」かつ同じ「項番」の場合、区別ができません。
そのため、「得意科目の評価」と「項番」をくっつけて区別できるようにします。
「&」を使って、2つの列の値を結合して新しい項番をつくり、区別できるようにします。
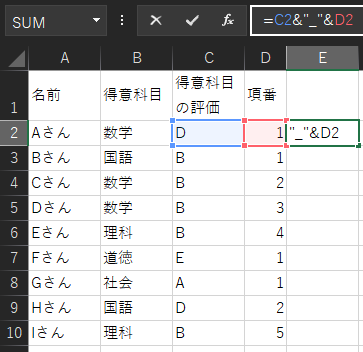
&を使うことで、セルや文字を結合できます。
例えば、このファイルで「=C2&D2」と入力すると、結果は「D1」と表示されます。
この数式では、C2セルとD2セルの値の間に「_」の文字を入れる、という処理を行います。
「_」を入れることで、「得意科目の評価」が数字の場合でも「得意科目の評価」と「項番」を区別できます。
もし、「得意科目の評価」か「項番」に「_」が含まれる場合、どちらにも含まれない文字(特殊記号等)に、C2セルとD2セルの値の間の文字を変えてください!
そうしないと正しく計算されません。
下までコピーすると次のようになります。
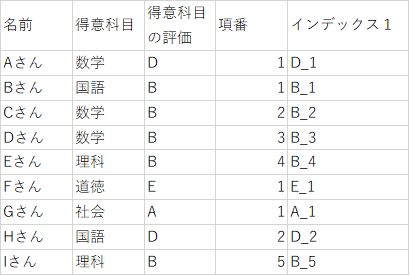
これが、同じ値毎に並び替える前準備になります。
とりあえずインデックス1という列名にします。
3. 各評価の総出現数を計算
「得意科目の評価」に何種類の値があるか調べます。
今回もCOUNTIFを使いますが、今度は上からではなく下から数えて何番目かということを調べます。
絶対参照セルをデータ列の一番上ではなく一番下にすることで、下から数えた場合の数式になります。
下までコピーすると次のようになります。
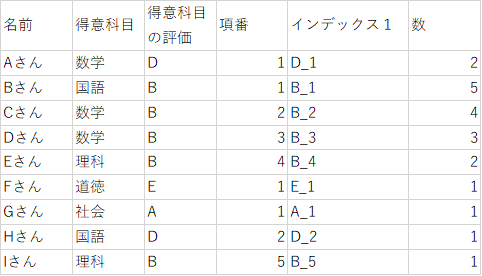
数_1という列名にしました。
「項番」列が1のときの「数」列を見ると、同じ評価がいくつあるか分かるようになっています。
これを利用して、並べ替えるための別の項番を新しく作ります。
4.評価ブロックごとの累積位置を計算
「項番」列が1のとき以外は一つ上のセルをコピーして、「項番」列が1のときは一つ上のセルの値に「数」列の値を足す数式を書きます。
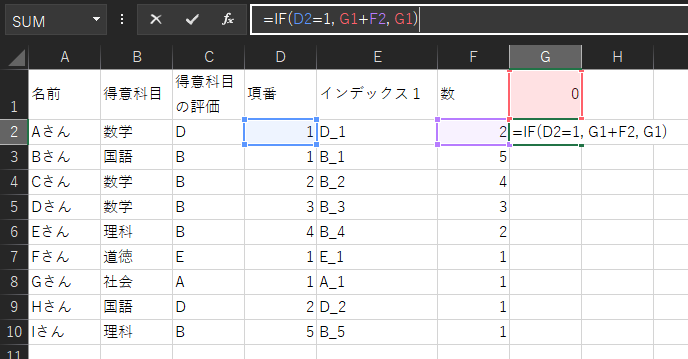
G1セルには0と入力してください。
下までコピーすると次のようになります。
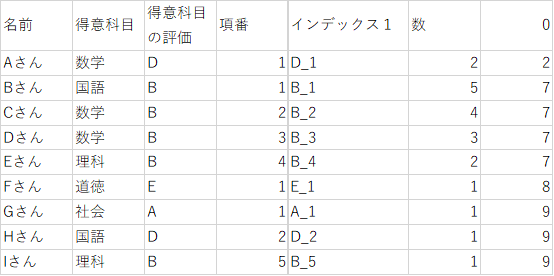
あと、4列分並び替える前準備が必要です。
5.連番を振る
この後の計算で連続した数字の列が必要なので、ここで追加します。
連番の追加方法はこちら。
6.累積位置から評価を逆引き
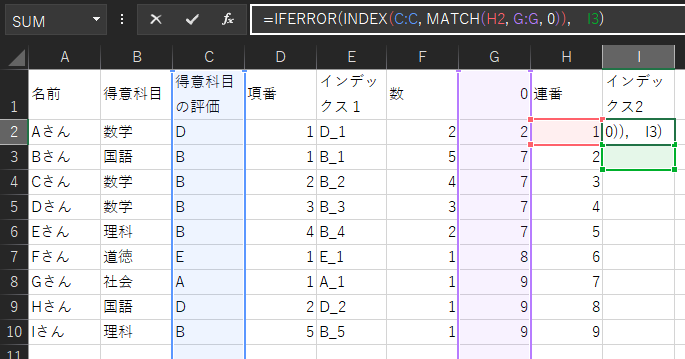
=IFERROR(INDEX(C:C, MATCH(H2, G:G, 0)), I3)この式では、本来2列に分けれた処理を1つにしています。
構造としては、
INDEX(C:C, MATCH(H2, G:G, 0))を計算した後に、その値がエラーの場合には、一つ下のセルをコピーするようになっています。
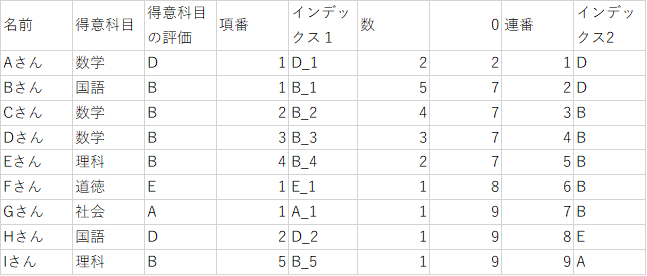
「INDEX(C:C, MATCH(H2, G:G, 0))」では、「連番」列の値と、G列の値が一致すれば、同じ行の「得意科目の評価」の値を表示します。
G列に「連番」列の値が存在しなければエラーとなります。この時に、一つ下のセルをコピーします。
MATCH(検査値, 検査範囲, 0) は、「検査範囲」内で上から見て何番目の行に「検査値」と同じ値のセルがあるかを計算します。「検査範囲」に「検査値」が複数セル存在する場合、一番上の一致セルの行番号が表示されます。
INDEX(配列, 行番号)は、「配列」で指定した範囲内で、上から数えて「行番号」目のセルを表示します。
INDEX(配列, MATCH(検査値, 検査範囲, 0))は、「配列」と「検査値」の行範囲が同じであれば、「検査値」と同じ行にある「配列」のセルを表示させることができます。
7.同一評価内での連番を再計算
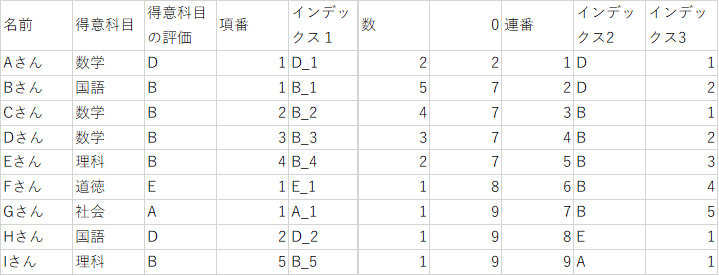
インデックス2の同一評価に異なる連番を振ります。
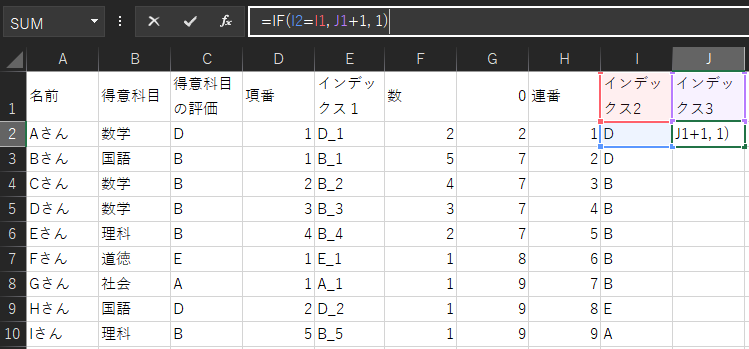
J2に着目して説明します。
I1とI2の値が同じ場合は、J1の値に1を足した値を表示し、I1とI2の値が異なる場合は、1を表示します。
8.新しい一意インデックスの生成
2.の一意のインデックス化のように、インデックス2とインデックス3を結合します。
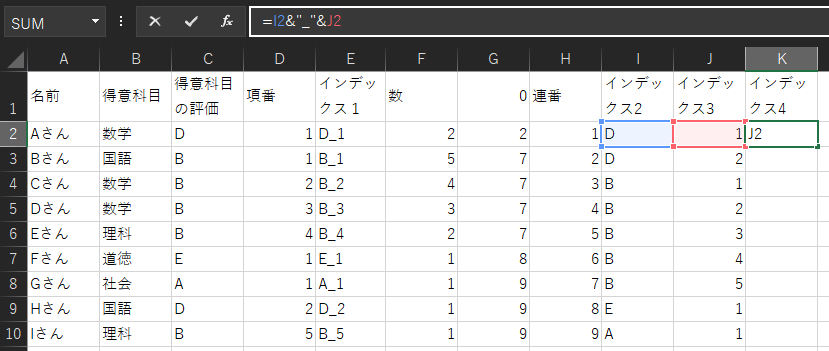
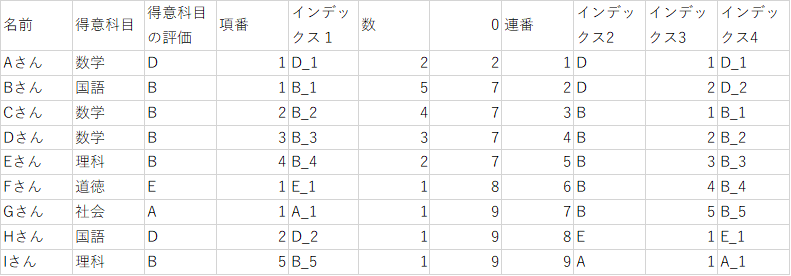
これで並び替えの準備ができました。
インデックス4はインデックス1を綺麗に並び替えた形だと分かります。
9.元データへの逆参照
INDEX(配列, MATCH(検査値, 検査範囲, 0))で、元データへの逆参照をします。
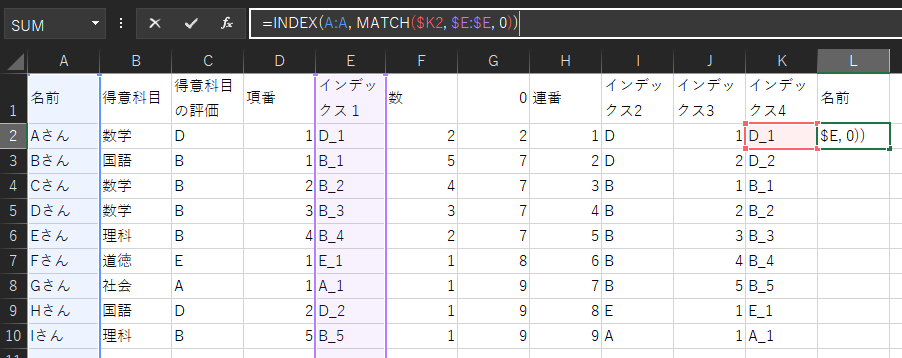
「配列」を「名前」列、「検査値」を「インデックス4」列の同じ行のセルで固定、「検査範囲」を「インデックス1」列で固定します。
このセルを、1.で行ったように、今度は右側にドラッグしてコピーすると、他の元データも逆参照できます。
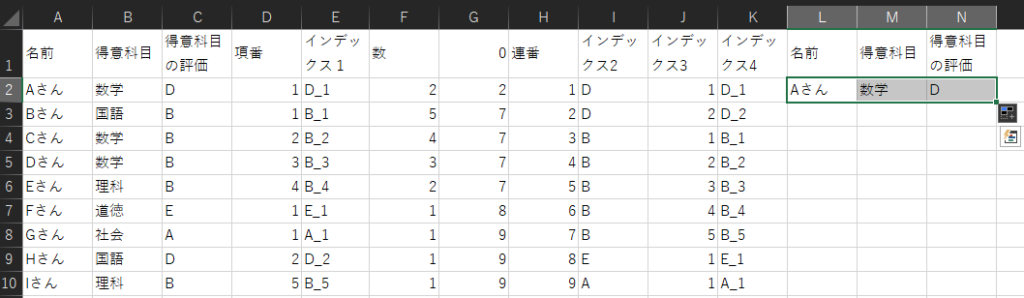
後は今までと同様、下にコピーします。
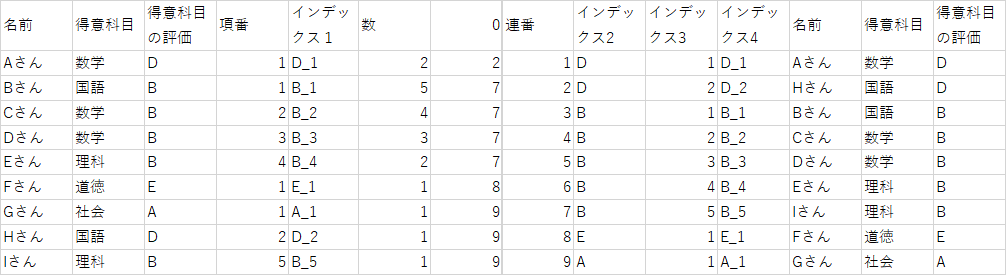
これで「得意科目の評価」毎にまとまった状態で並び替えることができました。
お疲れ様でした。
まとめ
excelファイルを載せておきます。
これをそのまま二次配布や再配布をする際は、問い合わせフォームからご連絡お願い致します。
少しでも改変された場合は連絡不要です。
この処理方法の問題点としては、複雑で可読性も低い点です。
元の順番が変わっても問題ない場合は、SORT関数を使用した方が可読性は高くなります。
また、1セル毎に検索範囲が全て異なるCOUNTIF関数にも問題があり、パソコンの性能によっては、データの行数が多くなると処理に非常に時間がかかる場合があります。
その様な場合はテーブルのフィルターを組み合わせて使う必要があり、数式のメリットである元データが変わった場合でもすぐに計算が終わる、という点がほぼ意味をなさなくなります。
大規模データでも比較的軽量に動く処理方法を現在模索中です。
アイデアお持ちの方いらっしゃいましたらお教えいただけると助かります。
こちらの記事が皆さんの一助になれば幸いです。

コメント